500彩票接口 双色球:出球顺序
http://datachart.500.com/ssq/history/newinc/outball.php
双色球:开奖信息
http://datachart.500.com/ssq/history/newinc/history.php
接口居然支持limit
http://datachart.500.com/ssq/history/newinc/history.php?limit=100000&sort=0
https://blog.csdn.net/weixin_36751895/article/details/78265985
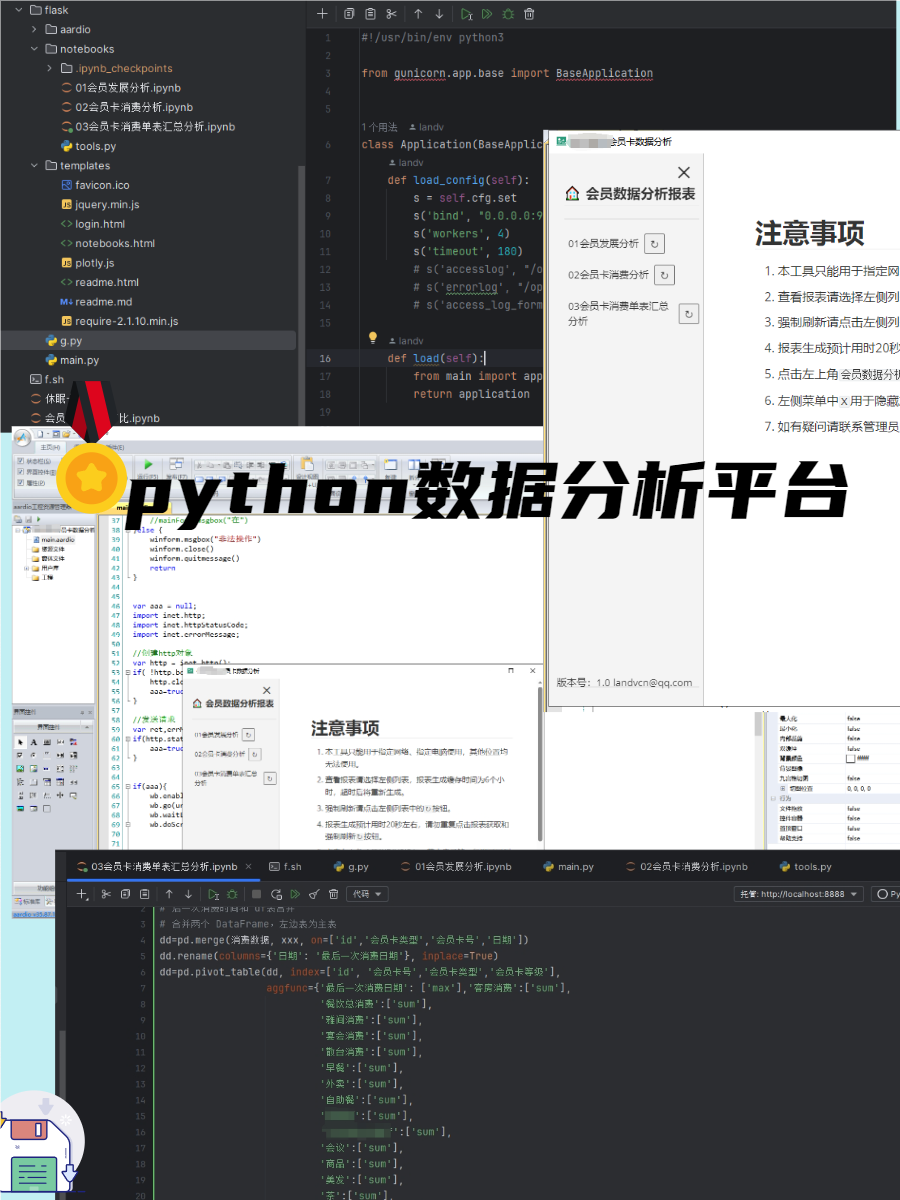
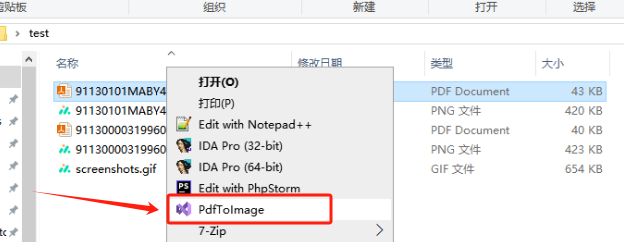
Python双色球爬虫
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 import requestsfrom lxml import etreeimport matplotlib.pyplot as pltfrom pandas import Seriesurl = "http://datachart.500.com/ssq/history/newinc/history.php?start=00001&end=18154" response = requests.get(url) response = response.text selector = etree.HTML(response) reds = [] blues = [] for i in selector.xpath('//tr[@class="t_tr1"]' ): red = i.xpath('td/text()' )[1 :7 ] blue = i.xpath('td/text()' )[7 ] for j in red: reds.append(j) blues.append(blue) s_blues = Series(blues) s_blues = s_blues.value_counts() s_reds = Series(reds) s_reds = s_reds.value_counts() from lxml import etreeimport matplotlib.pyplot as pltfrom pandas import Seriesurl = "http://datachart.500.com/ssq/history/newinc/history.php?start=00001&end=18154" response = requests.get(url) response = response.text selector = etree.HTML(response) reds = [] blues = [] for i in selector.xpath('//tr[@class="t_tr1"]' ): red = i.xpath('td/text()' )[1 :7 ] blue = i.xpath('td/text()' )[7 ] for j in red: reds.append(j) blues.append(blue) s_blues = Series(blues) s_blues = s_blues.value_counts() s_reds = Series(reds) s_reds = s_reds.value_counts() def autolabel (rects ): for rect in rects: height = rect.get_height() plt.text(rect.get_x(), 1.02 *height, "%s" % height) labels = s_blues.index.tolist() sizes = s_blues.values.tolist() rect = plt.bar(range (len (sizes)), sizes, tick_label=labels) autolabel(rect) plt.show() labels2 = s_reds.index.tolist() sizes2 = s_reds.values.tolist() rect2 = plt.bar(range (len (sizes2)), sizes2, tick_label=labels2) autolabel(rect2) plt.show() def autolabel (rects ): for rect in rects: height = rect.get_height() plt.text(rect.get_x(), 1.02 *height, "%s" % height) labels = s_blues.index.tolist() sizes = s_blues.values.tolist() rect = plt.bar(range (len (sizes)), sizes, tick_label=labels) autolabel(rect) plt.show() labels2 = s_reds.index.tolist() sizes2 = s_reds.values.tolist() rect2 = plt.bar(range (len (sizes2)), sizes2, tick_label=labels2) autolabel(rect2) plt.show()
Python大乐透爬虫
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import requestsfrom lxml import etreeimport matplotlib.pyplot as pltfrom pandas import Seriesurl = "http://datachart.500.com/dlt/history/newinc/history.php?start=00001&end=18154" response = requests.get(url) response = response.text selector = etree.HTML(response) reds = [] blues = [] for i in selector.xpath('//tr[@class="t_tr1"]' )[1 :]: red = i.xpath('td/text()' )[1 :6 ] blue = i.xpath('td/text()' )[6 :8 ] for j in red: reds.append(j) for k in blue: blues.append(k) s_blues = Series(blues) s_blues = s_blues.value_counts() s_reds = Series(reds) s_reds = s_reds.value_counts() def autolabel (rects ): for rect in rects: height = rect.get_height() plt.text(rect.get_x(), 1.02 *height, "%s" % height) labels = s_blues.index.tolist() sizes = s_blues.values.tolist() rect = plt.bar(range (len (sizes)), sizes, tick_label=labels) autolabel(rect) plt.show() labels2 = s_reds.index.tolist() sizes2 = s_reds.values.tolist() rect2 = plt.bar(range (len (sizes2)), sizes2, tick_label=labels2) autolabel(rect2) plt.show()
http://datachart.500.com/dlt/history/newinc/history.php?start=00001&end=99999
python https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
这篇文档介绍了BeautifulSoup4中所有主要特性,并且有小例子.让我来向你展示它适合做什么,如何工作,怎样使用,如何达到你想要的效果,和处理异常情况.
golang html 解析库
goquery: golang 使用这个吧,使用人数多,有完整手册,相比Python的bs4来说,还是Python给力
https://github.com/PuerkitoBio/goquery
soup:
https://github.com/anaskhan96/soup
https://godoc.org/github.com/anaskhan96/soup

 微信
微信