腾讯云函数scf
腾讯云
【腾讯云】云服务器等爆品抢先购,低至4.2元/月
https://cloud.tencent.com/act/cps/redirect?redirect=2446&cps_key=4f43721dde3f6683cb65674effd3c640&from=console

函数服务
Serverless:https://console.cloud.tencent.com/scf/list?rid=1&ns=default
函数手册:https://cloud.tencent.com/document/product/583
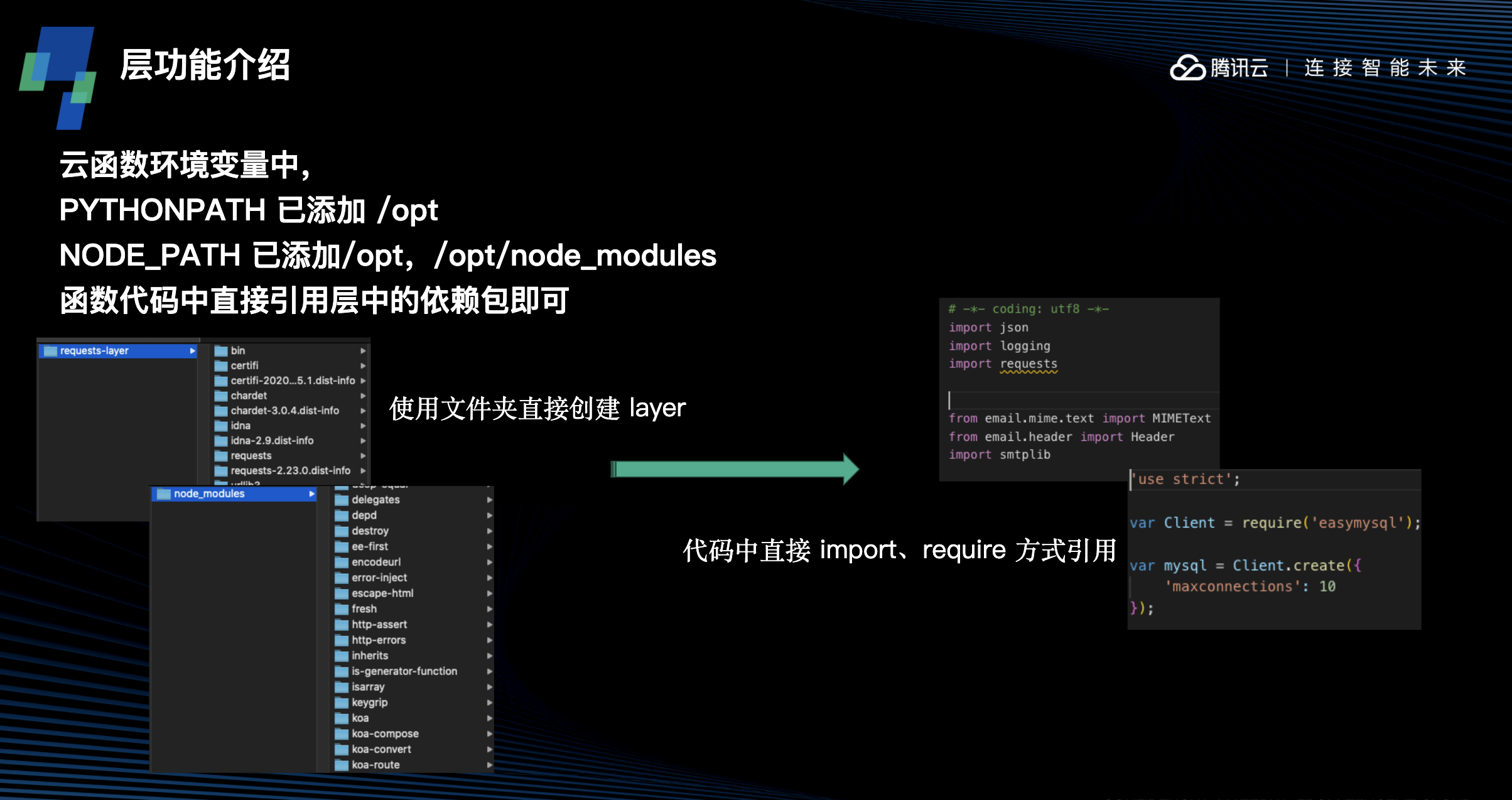
如何借助 Layer 实现云函数快速打包轻松部署
在使用云函数进行项目开发的时候,当函数数量变多后,您是否遇到函数的依赖库的管理问题?
由于云函数在创建或更新时,需要将函数的业务代码,和依赖库一同打包上传,因此在本地开发时,也经常是将依赖库和业务代码放置在一个文件夹下。
在这种情况下
每个云函数的代码目录下均有一套依赖库代码,而这其中有很多在若干个函数中都是重复的,不但占用了大量的空间,而且管理麻烦,在某些依赖库需要进行升级时,要进入到每个函数项目中去检查依赖关系和升级操作。
另一方面,这些依赖库通常不会有大的变动,但是却需要在每次函数进行更新时,都要和业务代码一同打包上传,导致实际的代码更新可能就一两行,但是需要生成一个十几兆甚至几十兆的包去上传,在网络环境不好的情况下还需要忍受缓慢的上传速度。
解决方案来了
近期,腾讯云的 SCF 云函数推出了层功能,是为了这类不经常变动的依赖库或静态文件而准备的产品功能。
通过使用层功能来存储及管理依赖库,并在使用时按需与函数进行绑定,就可以实现依赖库的多函数共享,仅需上传一份,就可以在多个要使用到的函数中绑定并引用。
通过与云函数绑定的使用方式,也就意味着不需要在云函数的业务代码中再附上相应的依赖库了,可以将业务代码和依赖库分开进行管理和部署,降低云函数每次上传时需要提交的包大小,加快上传更新的速度。
在实际案例介绍前,先介绍一下层的功能点
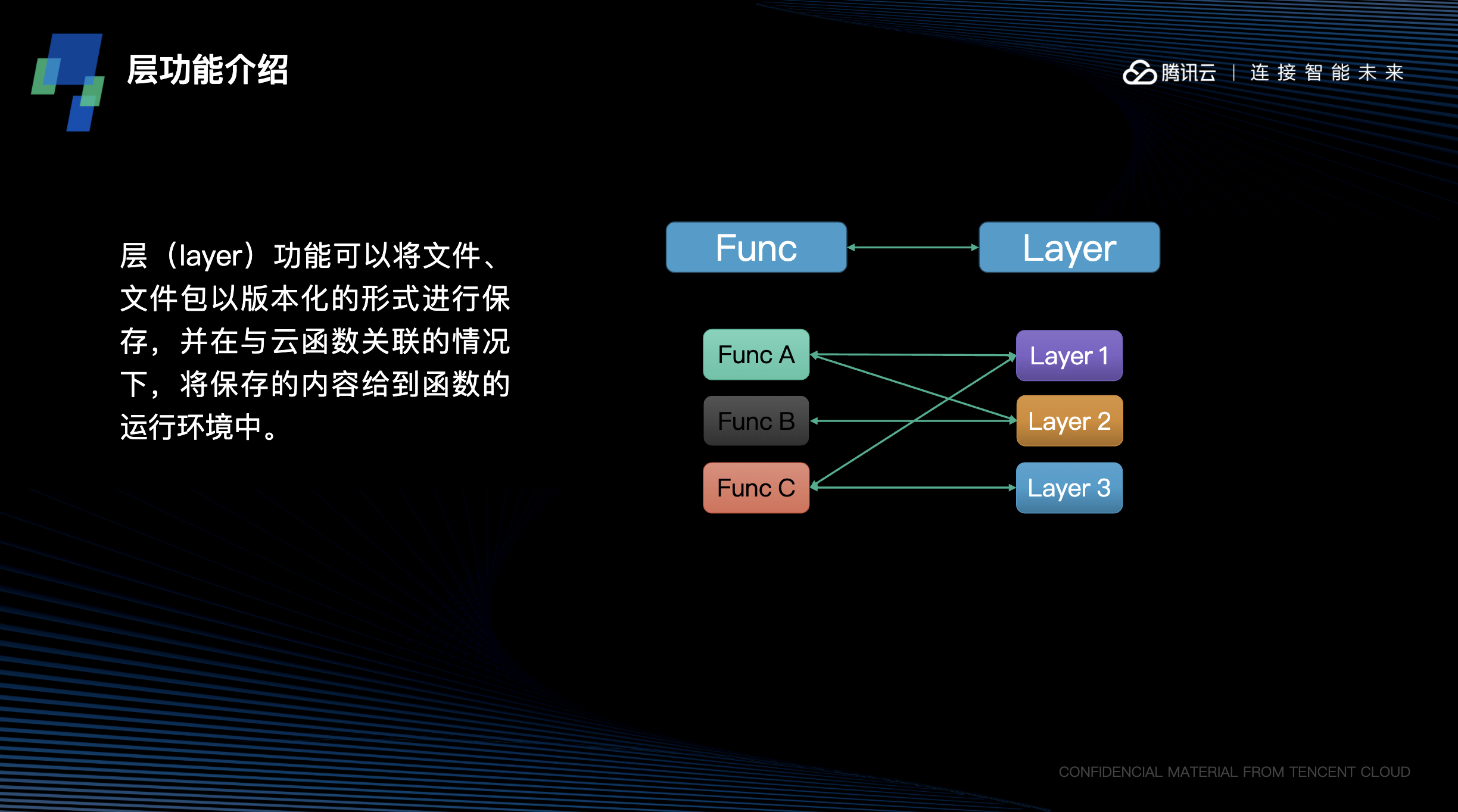
层作为一个和云函数独立的资源,有独立的创建、管理流程。和函数创建类似,可以通过上传 zip 包,或者控制台上选择文件夹,或者将 zip 包提前上传 cos 后再引用的方式,来将文件内容提交到云上,并创建好层。每一个提交到层中的文件包,都将生成一个新的版本。
因此,在创建好一个层以后,就将具有了第一个版本;而后续如果依赖库或文件内容有升级,可以继续更新层,并生成新的版本,版本号依次增大。在创建层,或发布新版本的时候,还可以指定当前层所可支持的 runtime,这样相应 runtime 的函数,才可以浏览或绑定当前层。
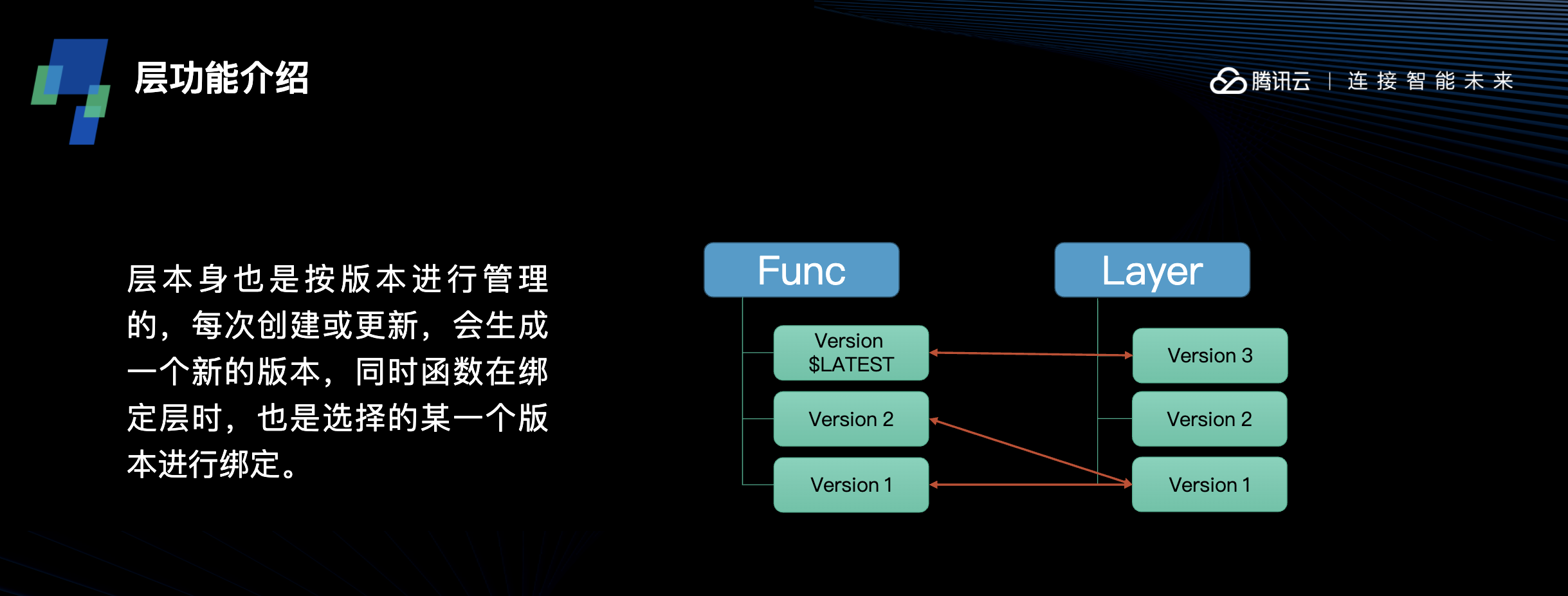
在使用层时,通过云函数与具体层的具体版本绑定,来实现层内容的引入和使用。在函数的配置管理界面,新增加了层的绑定配置界面。通过选择层及期望绑定的版本,就可以完成绑定操作。绑定了层以后,在函数运行时,运行环境中的 /opt 目录下就会有层的内容。当然,系统中的 NODE_PATH,PYTHONPATH 已经指定好了 /opt 目录,绑定好的层中如果包含有依赖库,在函数代码中可以直接通过 import,require 等方法直接引用,与常规写法一致,不需要额外进行路径的指定。同时,目前一个函数支持最多绑定 5 个层的版本,因此可以通过这种方法,将所需的依赖库分别引入到层中。
在多个层绑定到同一个函数时,层之间有一定的顺序关系。层是按照顺序关系依次加载的,如果在相同路径下有同名文件,会产生后加载的文件覆盖先加载文件的问题,需要在此处注意多个层绑定时是否会有内容覆盖,以及加载循序是否是按自身的控制需要来的。另一方面,层与函数的绑定关系,也作为函数的配置保存。$LATEST版本的函数可以按需修改调整绑定配置,而一旦发布版本后,生成的函数版本中的配置就固定了,无法再次修改。因此,通过发布版本来固化已经开发完成的版本,可以避免函数代码或层内容的修改导致的代码不可用。

接下来,我们通过一个使用案例来介绍层功能的使用。
在这个案例中,我们将实现一个拨测网站,并在检测到异常时发送消息到 cmq 消息队列中的云函数。这个云函数由 python 写成,将使用两个依赖库,requests 库用来实现 url 地址的 http 访问检测,及 cmq 库用来实现向 cmq 的队列发送消息。
在创建函数前,我将使用这两个库分别创建两个层,并在后续将函数与这两个层绑定来使用依赖库。
首先在本地分别创建两个文件夹: requests-lib 和 cmq-lib
通过命令行进入 requests-lib 文件夹后,执行命令
pip install requests -t
在此目录下完成 requests 库的下载安装。而在 cmq-lib 文件夹内,我们通过下载或 clone https://github.com/tencentyun/cmq-python-sdk 项目,将 cmq 的 sdk 下载到本地。
接下来,使用这两个文件夹分别创建两个层,同样命名为 requests-lib 和 cmq-lib,
通过直接选择文件夹创建,并选择好适配 runtime 为 python2 ,在创建完成两个层后,他们都具有版本 1 可供函数绑定。
同时,我在相同地域下也创建好了名字为 testq 的 cmq 队列,并根据 sdk 需要准备好了账号 id,secret id,secret key 等信息。
接下来,我将使用如下代码创建函数 detect-sendmsg,实现 url 的拨测,并向 cmq 消息队列中发送消息
代码中的 appid、secretid、secretkey,需要替换为自身账号下的相关内容。
1 | # --- coding: utf8 --- |
使用此代码创建好函数,并在函数的层管理中,分别绑定好 requests-lib、cmq-lib 两个层。由于这两个层没有重复部分,因此可以以任意顺序绑定。
完成绑定后,可以直接通过控制台触发函数,查看运行情况。一切正常的情况下,可以看到拨测的过程,以及消息发送到消息队列中的记录。同时,也可以到消息队列的对应 queue 中,通过获取消息,获取到发送到其中的消息记录。
从这个例子中可以看到
函数代码中应用了 requests 库,和 cmq 的 sdk,但并未通过和函数一同打包上传来实现,而是将依赖库放置到层里面后,通过绑定关系来引用。通过这种方式,如果下次我们启动一个新的函数也需要使用到 requests 库,直接与已有的层绑定即可使用,而同样不需要再次打包上传。而函数代码仅一个文件,不需要带有较大的依赖库,也可以降低每次更新上传时的包大小,甚至直接快速的使用 WebIDE 来进行编辑就行。
层的功能为依赖库和不经常修改的静态文件提供了新的存储方案,与函数的剥离使得这类文件能够多函数复用,版本化管理;随着层功能的发展,腾讯云 Serverless team 也将进一步拓展层功能的使用,包括了在开发工具中实现自动化的层创建和绑定、层的共享、提供公共层供用户直接复用等,都已经在 roadmap 中,将在接下来的发展中逐步落地,供云函数的开发体验更加便利。
在云函数中使用真正serverless的SQL数据库sqlite
原文:https://cloud.tencent.com/developer/article/1984526
测试sqlite3,它通过node-gyp本地构建依赖了一些基于本地运行环境的c的模块,并且它还需要通过v3或者v6的node-API来访问它们,而腾讯云的云函数运行环境只能支持v3的node-api接口,5.0.3以上的版本需要用node11或者node8的环境来构建层才能让层使用v3的版本,不过就算这样也没用,5.0.3和更高的版本上需要的libm.so.6 和 libstdc++.so.6版本都超过了云函数运行环境的版本(除非用一些特殊的方法)。所以最后能用的最高版本的sqlite3是5.0.2。本机mac上做出来的layer放到腾讯云上是用不了的,所以要在docker里面做一下:
1 | echo "cd /usr/src;npm install sqlite3@5.0.2 --save">tmp.sh |
这样就能得到一个5.0.2版本的sqlite3的层:
测试一下:
1 | ; |
性能表现一般般。能不能更快一点呢?又找到了一个更快的 bettersqlite,同时还发现有人为aws lambda制作了一个基于node12的layer生成工具,读了一下代码,其实基本上就是做了这么一件事:
1 | docker run --rm -v "$PWD":/var/task lambci/lambda:build-nodejs12.x npm install better-sqlite3@6.0.1 --save |
当然也不是一定要用他那个node12镜像,这样也可以:
1 | echo "cd /usr/src;npm install better-sqlite3@6.0.1 --save">tmp.sh |
然后就生成了一个node12的better-sqlite3@6.0.1的layer(6.0.1后面的下一个版本就是7.0.0,开始要求libstdc++.so.6支持CXXABI_1.3.9,而腾讯云scf的运行环境下最高只有CXXABI_1.3.8,做出来layer也运行不了):
链接: betterSqliteLambdaLayer.zip百度网盘备份
直接开一个node12的云函数调用一下:
1 | ; |
密集读写的时候,同步操作果然比异步操作快得多。因为要测试实际工作性能,这次数据库文件没有挂到/tmp下而是挂在/mnt/目录下,因此需要挂载一个CFS来做文件系统。受限于cfs的延迟,单次简单查询操作毫秒级,单次写操作十多毫秒,都比云开发数据库快了一个数量级。做小数据量小型应用够用了。
注意这是单个进程的读写。sqlite在多进程并发写的时候是有可能出现死锁的,尤其是bettersqlite这种同步式的操作。而我们做serverless最喜欢的就是处理瞬间的访问量剧增,那怎么办呢?一个解决方案是读写分离到不同的scf中,限制写的scf上限只能一个,这也容易出现写瓶颈。另一个更好的办法是利用云函数的单实例多并发特性,用单一个云函数来处理大量的并发(因为实例分配到的cpu资源与内存相关联,所以遇到更高并发量的时候单个实例的处理能力还可以通过调整实例内存来提升),这样就可以尽可能的避免写竞争的情况了。当然也可以两个办法一起上,读写分离并且把写请求都交给同一个单实例多并发的云函数。
函数运行环境系统动态链接库版本太低?函数计算 fun 神助力分忧解难
背景
最近在处理线上工单的时候,遇到一个用户使用 nodejs runtime 时因为函数计算运行环境的 gcc 版本过低导致无法运行的问题,觉得非常有意思,所以深入的帮用户寻找了解决方案。觉得这个场景应该具有一定的通用性,所以在这篇文章里面重点的介绍一下如何使用函数计算的周边工具 fun 解决因为 runtime 中系统版本导致的各种兼容性问题。
场景介绍
用户问题
简要描述一下用户当时遇到的问题:
用户使用函数计算的 nodejs8 runtime,在本地自己的开发环境使用 npm install couchbase 安装了 couchbase 这个第三方库。couchbase 封装了 C 库,依赖系统底层动态链接库 libstdc++.so.6。因为用户自己的开发环境的操作系统内核比较新,所以本地安装、编译和调试都比较顺利。所以,最后按照函数计算的打包方式成功创建了 Function,但是执行 InvokeFunction 时,遇到了这样的错误:
1 | "errorMessage": "/usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by /code/node_modules/couchbase/build/Release/couchbase_impl.node)", |
错误发生的原因如堆栈描述,即没有 CXXABI_1.3.9 这个版本,可以看到函数计算 nodejs 环境中的支持情况:
1 | root@1fe79eb58dbd:/code# strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 |grep CXXABI_ |
升级底层系统版本的代价比较大,需要长时间的稳定性、兼容性测试和观察,所以,为了支持这类使用场景,我们希望能够有比较简单的方式绕行。
场景复现和问题解决
前提:先按照 fun 的安装步骤安装 fun工具,并进行 fun config 配置。
在本地很快搭建了一个项目目录:
1 | - test_code/ |
其中 index.js 和 template.yml 的 内容分别为
1 | # index.js |
为了能够在本地模拟函数计算的真实环境进行依赖包安装和调试,这里生成一个 fun.yml 文件用于 fun install 安装使用,内容如下:
1 | runtime: nodejs8 |
un.yml中参数说明:
前面的分析已经了解到函数计算 nodejs8 runtime 的 libstdc++.so.6 的版本偏低,所以,我们找到一个更新的版本来支持,见新版本的 libstdc++.so.6 的 CXXABI_ 参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14strings .fun/root/usr/lib/x86_64-linux-gnu/libstdc++.so.6|grep CXXABI_
CXXABI_1.3
CXXABI_1.3.1
CXXABI_1.3.2
CXXABI_1.3.3
CXXABI_1.3.4
CXXABI_1.3.5
CXXABI_1.3.6
CXXABI_1.3.7
CXXABI_1.3.8
CXXABI_1.3.9
CXXABI_1.3.10
CXXABI_TM_1
CXXABI_FLOAT128
执行 fun install 命令
安装各种第三方依赖,显示如下:
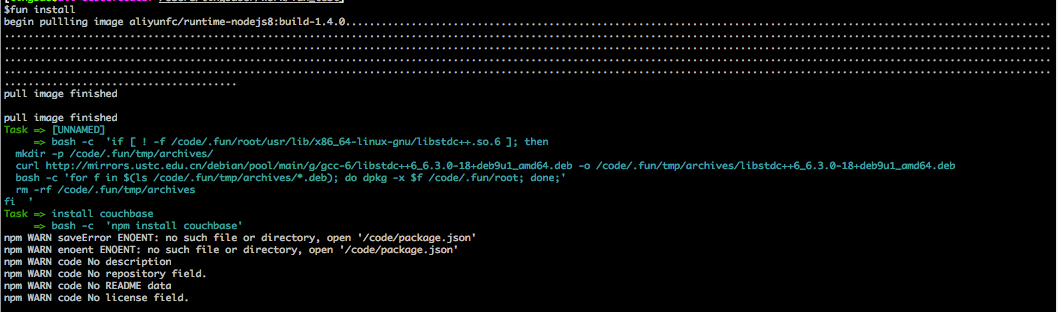
本地执行情况
执行 fun local invoke helloworld,可以看到执行成功的效果:
1 | fun local invoke helloworld |
发布上线
使用 fun deploy 发布上线,然后到控制台执行一下线上实际的运行效果:
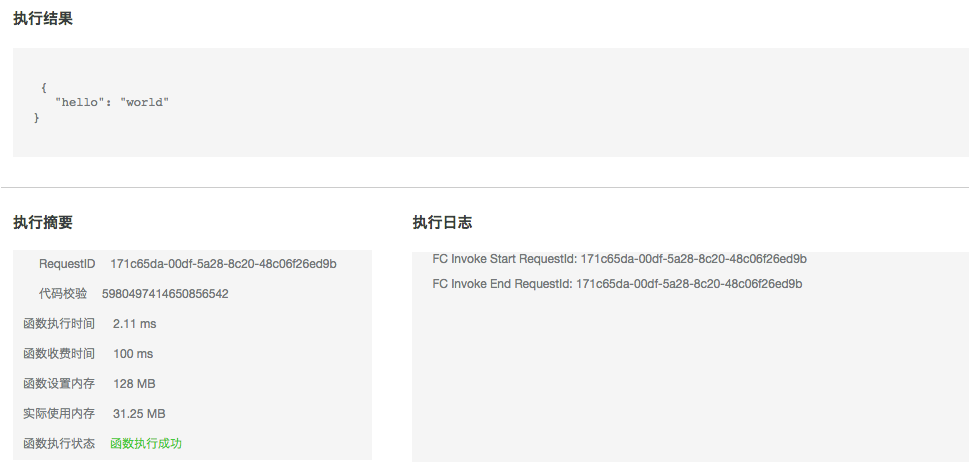
总结
fun install 功能能够将代码和依赖文件分离开,独立安装系统依赖文件,而且 fun local 和 fun deply 都能够自动帮你设置第三方库的依赖引用路径,让您无需关心环境变量问题。
本文的解法只是提供了一个对于系统版本偏低无法满足用户一些高级库使用需求时的简单绕行方案,仅供参考,对于一些复杂的环境依赖问题,可能还需要具体情况具体分析。
更多参考:
CFS
文件存储
https://cloud.tencent.com/product/cfs
文件存储(Cloud File Storage,CFS)为您提供安全可靠、可扩展的共享文件存储服务。文件存储可与腾讯云服务器、容器服务、批量计算等服务搭配使用,为多个计算节点提供容量和性能可弹性扩展的高性能共享存储。腾讯云文件存储的管理界面简单、易使用,可实现对现有应用的无缝集成;按实际用量付费,为您节约成本,简化 IT 运维工作。
要想使用CFS需要借用VPC(私有网络)打通vps、云函数链接
VPC
私有网络 VPC
https://cloud.tencent.com/product/vpc
私有网络(Virtual Private Cloud,VPC)是基于腾讯云构建的专属云上网络空间,为您在腾讯云上的资源提供网络服务,不同私有网络间完全逻辑隔离。作为您在云上的专属网络空间,您可以通过软件定义网络的方式管理您的私有网络 VPC,实现 IP 地址、子网、路由表、网络 ACL 、流日志等功能的配置管理。私有网络还支持多种方式连接 Internet,如弹性 IP 、NAT 网关等。同时,您也可以通过 VPN 连接或专线接入连通腾讯云与您本地的数据中心,灵活构建混合云。
在云函数 SCF上使用 CFS
https://cloud.tencent.com/document/product/582/47148
云函数(Serverless Cloud Function,SCF) 是腾讯云为企业和开发者们提供的无服务器执行环境,帮助您在无需购买和管理服务器的情况下运行代码。您只需使用平台支持的语言编写核心代码并设置代码运行的条件,即可在腾讯云基础设施上弹性、安全地运行代码。SCF 是实时文件处理和数据处理等场景下理想的计算平台。
SCF 是服务级别的计算资源,它的快速迭代、极速部署的特性天然需要存储与计算分离,而文件存储(Cloud File Storage,CFS)提供的高性能共享存储服务为 SCF 最佳的存储方案 。只需几步简单配置,您的函数即可轻松访问存储在 CFS 文件系统中的文件。SCF 使用 CFS 的优势如下:
- 函数执行空间不受限。
- 多个函数可共用一个文件系统,实现文件共享。
API网关
https://cloud.tencent.com/product/apigw
腾讯云 API 网关(API Gateway)是腾讯云推出的一种 API 托管服务,能提供 API 的完整生命周期管理,包括创建、维护、发布、运行、下线等。
可以配合COS、SCF
COS
对象存储 COS
https://cloud.tencent.com/product/cos
对象存储(Cloud Object Storage,COS)是由腾讯云推出的无目录层次结构、无数据格式限制,可容纳海量数据且支持 HTTP/HTTPS 协议访问的分布式存储服务。腾讯云 COS 的存储桶空间无容量上限,无需分区管理,适用于 CDN 数据分发、数据万象处理或大数据计算与分析的数据湖等多种场景。
CNS
DNS 解析 DNSPod
https://cloud.tencent.com/product/cns
DNSPod 提供快速、稳定且高可用的 DNS 解析服务,支持智能解析、流量调度、安全防护。
我使用的是 9.9/年 新春特惠
现在价格是99元/年,约 8.3元/月。原价188元/年。
使用免费版也可以,只是解析条数有限制。我主要是用于区分境内外便于加速github pages部署的hexo博客。
github pages A域名解析有四个IP地址,如果是免费版只能做两条负载均衡,下面的IP地址选择两个就好了。
1 | 185.199.108.153 |
CDN
https://cloud.tencent.com/product/cdn
内容分发网络 CDN
内容分发网络(Content Delivery Network,CDN)通过将站点内容发布至遍布全球的海量加速节点,使其用户可就近获取所需内容,避免因网络拥堵、跨运营商、跨地域、跨境等因素带来的网络不稳定、访问延迟高等问题,有效提升下载速度、降低响应时间,提供流畅的用户体验。
SSL证书
https://cloud.tencent.com/product/ssl
腾讯云可免费申请20个SSL证书。
SSL 证书(SSL Certificates)又叫服务器证书,腾讯云为您提供证书的一站式服务,包括免费、付费证书的申请、管理及部署功能。通过与业界知名的数字证书授权(CA)机构合作,为您的网站、移动应用提供 HTTPS 解决方案。
TDSQL-C MySQL 版
https://cloud.tencent.com/product/cynosdb
TDSQL-C MySQL 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库。融合了传统数据库、云计算与新硬件技术的优势,100%兼容 MySQL,为用户提供极致弹性、高性能、高可用、高可靠、安全的数据库服务。实现超百万 QPS 的高吞吐、PB 级海量分布式智能存储、Serverless 秒级伸缩,助力企业加速完成数字化转型。
hexo整体数据流转路径
发布博客
- github,hexo生成端>>github pages
- github,hexo生成端>>腾讯云COS
访问
landv.cn>>CNS>>境内>>CDN>>COS
landv.cn>>CNS>>境外>>github pages
waline评论
将采用三种方式进行评测
- waline.cn>>CNS>>API网关>>SCF>>TDSQL-C MySQL
- TDSQL-C MySQL 基于云函数部署的msyql,大约日消耗为1元。
- waline.cn>>CNS>>API网关>>SCF>>tidbcloud
- tidbcloud为免费类似mysql数据库,没有费用。
- waline.cn>>CNS>>API网关>>SCF>>VPS>>CFS>>sqlite3
- CFS消耗也可以忽略不计
 微信
微信- 支付宝
- QQ